❗Disclaimer: All opinions are my own.
Overview
All workloads (including containers) are powered by some form of compute device, but generally most software will at least use a CPU.
There are many CPU models available for usage, but the most important aspect in terms of running software is the CPU’s architecture (i.e. supported instruction set architecture for compute operations).
There is a diversity of CPU architectures available on cloud and on-premises, but only 2 are considered mainstream:
- x86_64 / amd64
- arm64 / aarch64
Containers are created from container images. These images are typically found in a container registry, such as DockerHub, as per the image below. Note the options for the operating system and the CPU architecture.
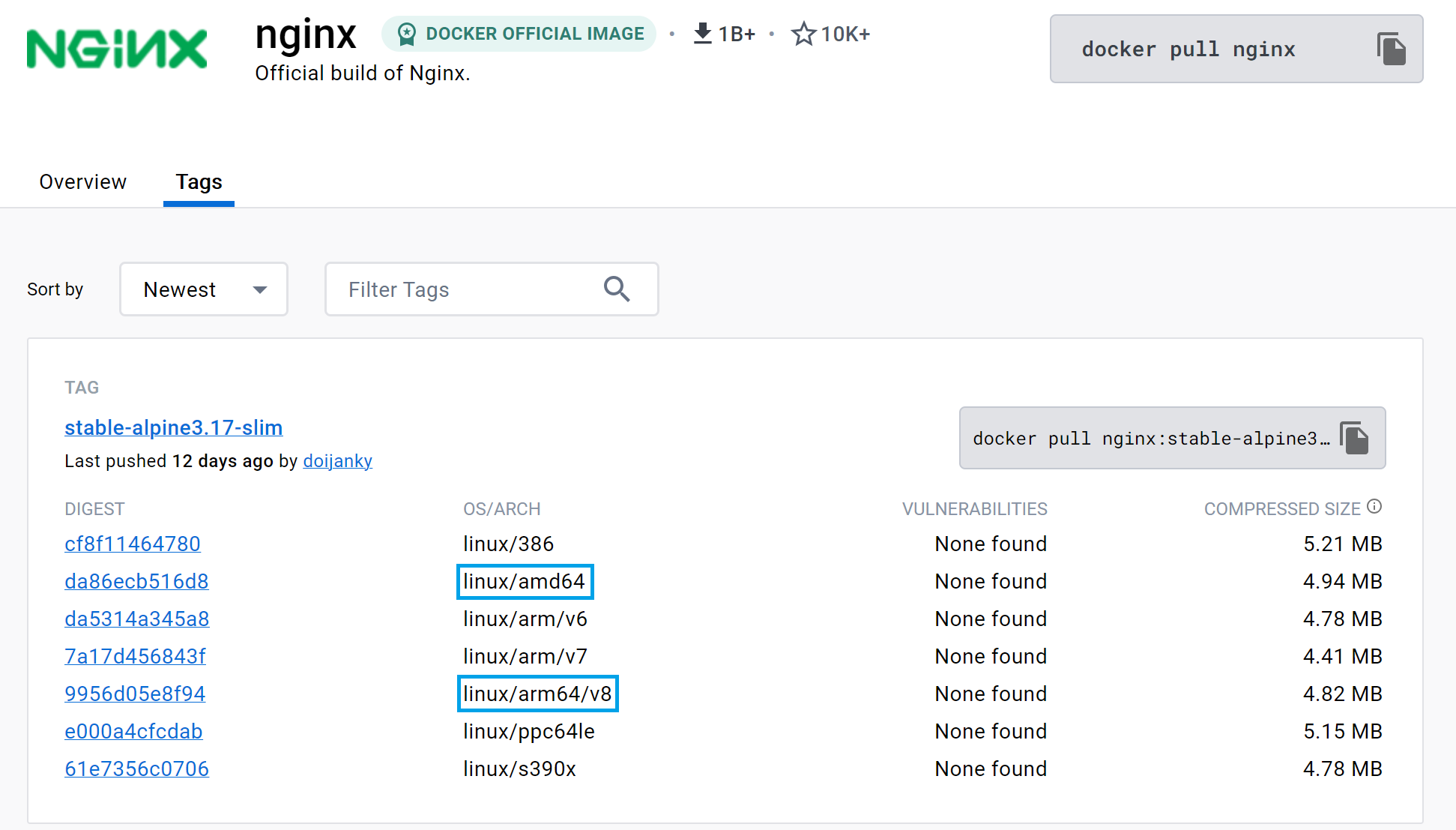
❗ Running an image not compatible with the CPU architecture or the OS’s supported binary formats will result in errors.
The ecosystem challenge
Almost all container images tend to be built for x86_64 by default, but not all have the arm64 versions.
However, given the increasing portfolio of compute options for arm64 both on cloud (e.g. AWS Graviton, Ampere Altra) and on-premises, this will likely change in time.
Multi-arch images powered by e.g. Docker manifest files have also become popular.
Running a multi-arch image and referencing it by e.g. name:version instead of name:version-cpu_arch makes container deployments easier because a command like
docker pullwill download the image matching the host.

However, not all manifest files will have both x86_64 and arm64 container images to point to. Validate if that’s the case like in the image below.
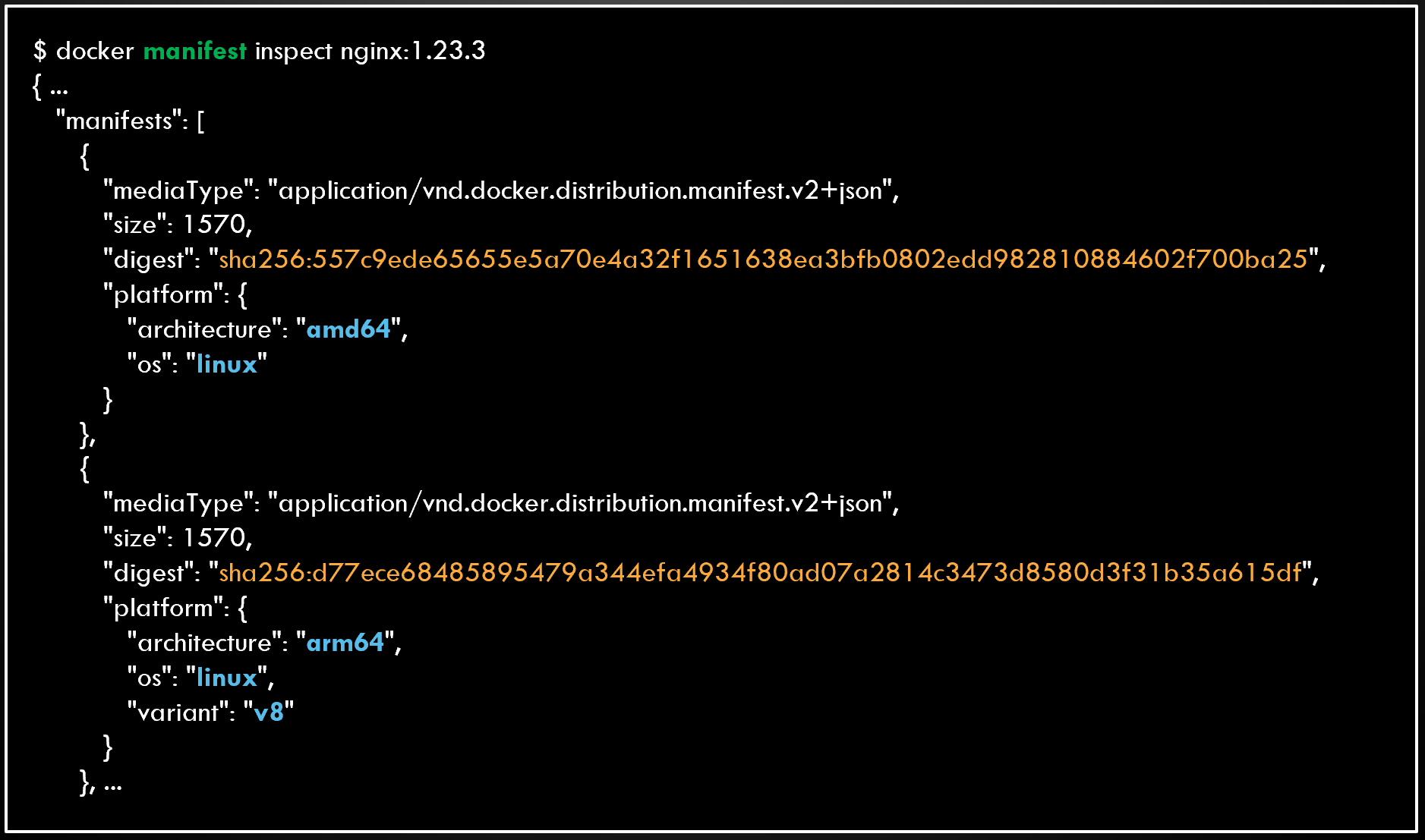
Popular container tooling (e.g. docker, podman, buildah) has various levels of support for arm64. One exception would be Cloud Native Buildpacks.
Common practices
A fan of docker buildx?
There are many sources online that mention docker buildx build --platform linux/arm64,linux/amd64 for building multi-arch images from a single host.
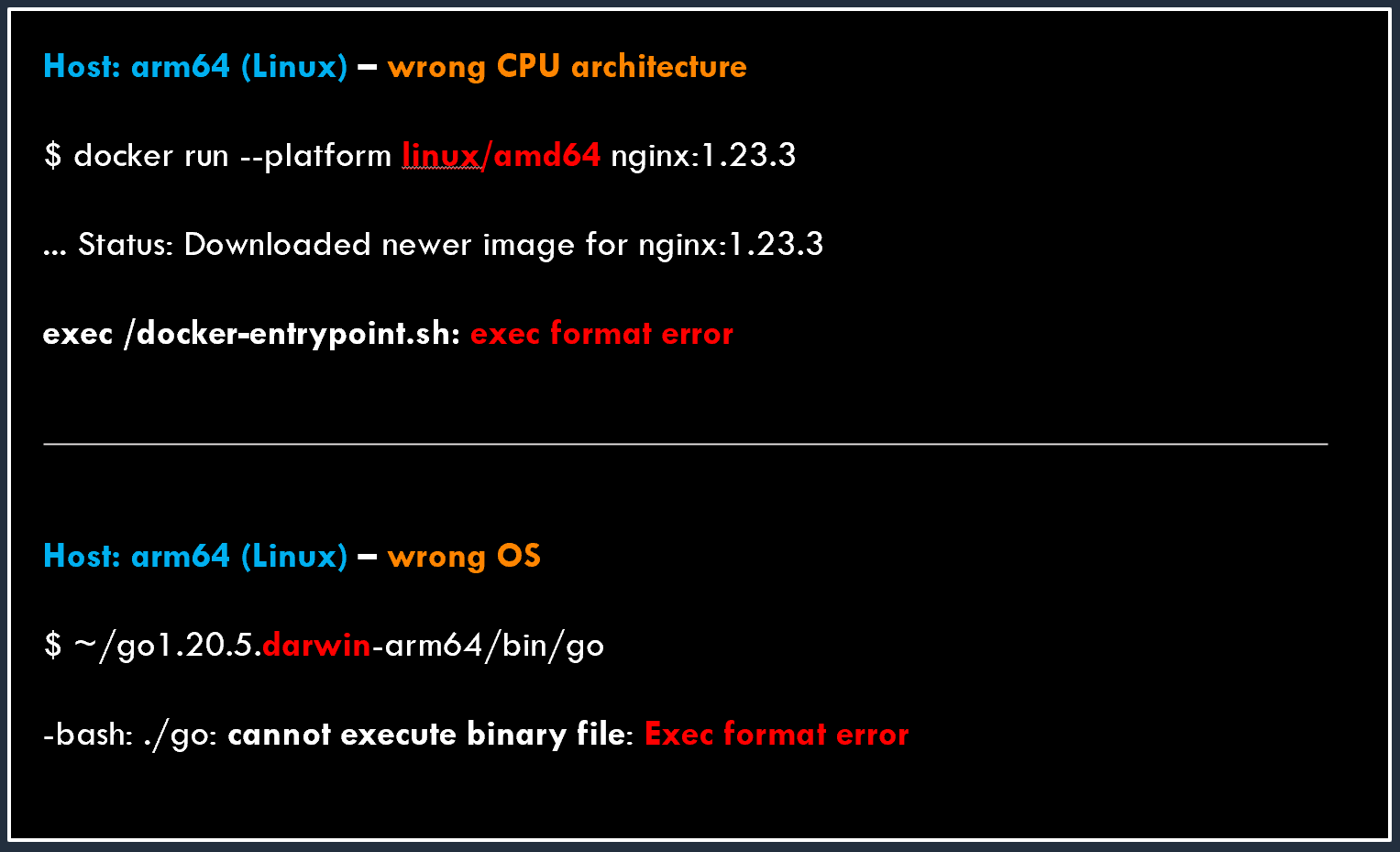
This is possible because of CPU architecture emulation. In short, the buildx plugin will use the qemu emulator to translate instructions between CPU architectures.
❗ “Sounds great! I should use it then, right?” -> For production, no.
At most, emulation should be used for prototyping or for workloads which are not compute-bound (e.g. doing data transfers).
Drawbacks of using emulation include:
- slow builds for anything CPU-intensive (e.g. takes 1 hr instead of 3 mins)
- runtime performance affected by usage of non-optimal instructions
- in rare cases, it makes mistakes leading to hard-to-debug errors
An example of emulation used when building containers is shown below. Note times will vary depending on container image and the workload in it. The lib-arm64 is an abstract name for a sample that builds an open-source software and all its dependencies from source.
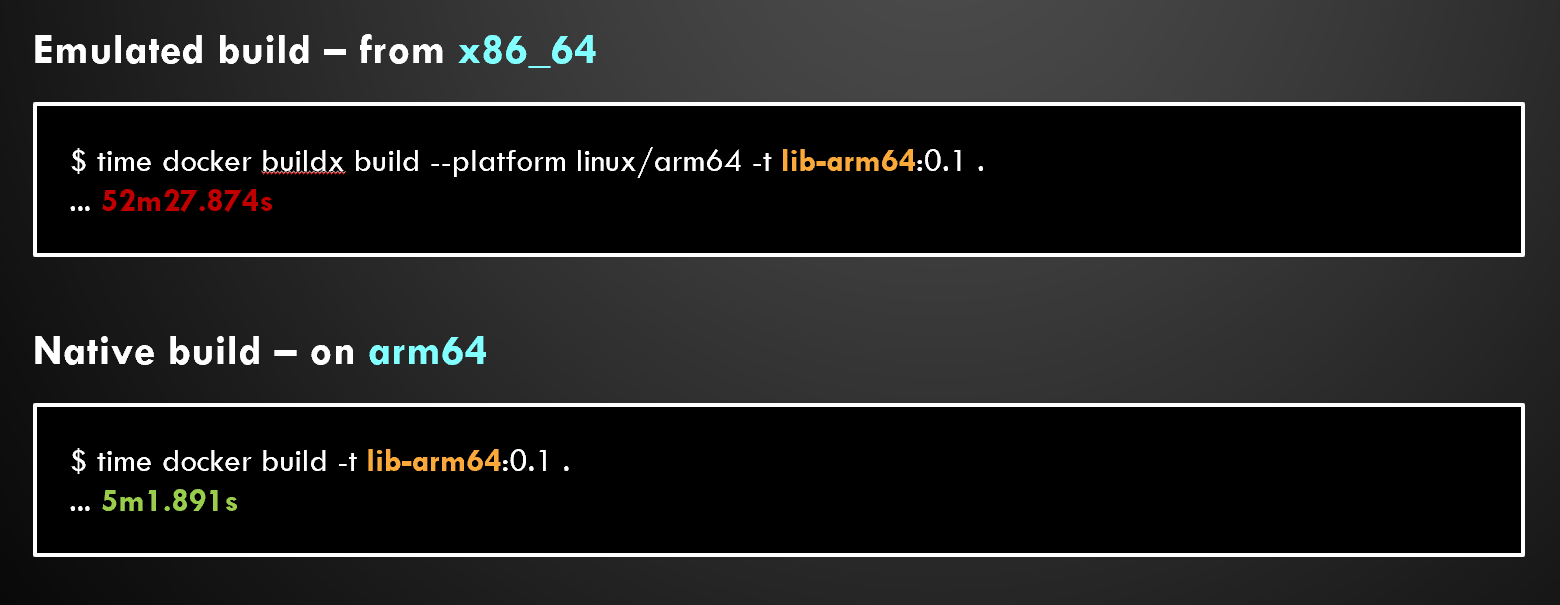
Best practice: use native builds (i.e. build your arm64 containers on an arm64 host)!
The same applies to all other tooling (e.g. podman, buildah) that allows multi-arch using emulation.
Are mixed-arch clusters a good idea?
It depends on the workload’s characteristics.
❗ The performance of x86_64 and arm64 tends to differ, especially for compute and memory-bound workloads.
Imagine the following scenarios where it could be an issue:
- a database cluster where the x86_64 readers finish data replication slower than arm64 readers. Your apps could be getting different (stale) results.
- load balancers typically don’t offer custom routing to instances with different performances (e.g. x86_64 completes request in 5 mins and arm64 in 2 mins).
- scaling is harder to tune. If you use CPU utilization, for x86_64 with SMT you might pick 60% (up) and 30% (down), while on arm64 80% (up) and 40% (down).
However, if you’re able to control or mitigate any unexpected behaviour, you could use mixed-arch clusters to pick the right instance type for a workload (e.g. x86_64 for DB query 1, arm64 for DB query 2).
Mixed-arch also gives you a wider range of compute options, so you have more capacity available.
Container builds
Lift-and-shift from x86_64 to arm64 (Nice!)
Let’s look at this example which works for both x86_64 and arm64 container builds.
A Dockerfile:
FROM public.ecr.aws/lts/ubuntu:20.04_stable
WORKDIR /home/app
COPY requirements.txt .
RUN apt update && \
apt install -y --no-install-recommends python3-pip && \
pip install -r requirements.txt
with requirements.txt:
numpy==1.21.6
scikit-learn==1.2.0
matplotlib==3.6.1
Note the following:
- the base image (FROM) is multi-arch and includes x86_64 and arm64
- requirements.txt is a text file which is platform-agnostic
- apt has default repos that provide package python3-pip for both x86_64 and arm64
- the 3 packages (and versions) installed with pip exist for both x86_64 and arm64
Most packages with Python will be platform-agnostic because they’re written in pure Python. However, some packages have strict performance requirements such as numpy which also uses C. The usage of a compiled language like C means we need binaries for the OS/arch we use.
Notice some of the binaries in https://pypi.org/project/numpy/1.21.6/#files:
- x86_64: numpy-1.21.6-…-manylinux_…_x86_64…whl
- arm64: numpy-1.21.6-…-manylinux_…_aarch64…whl
In many cases, such as this one, it means you only maintain one e.g. Dockerfile for both CPU architectures.
When x86_64 and arm64 diverge (Ohh!)
Older software
As a general rule, newer software versions tend to have arm64 support and some even have performance optimizations.
If we changed the example above to numpy==1.18.5, we’d notice the following:
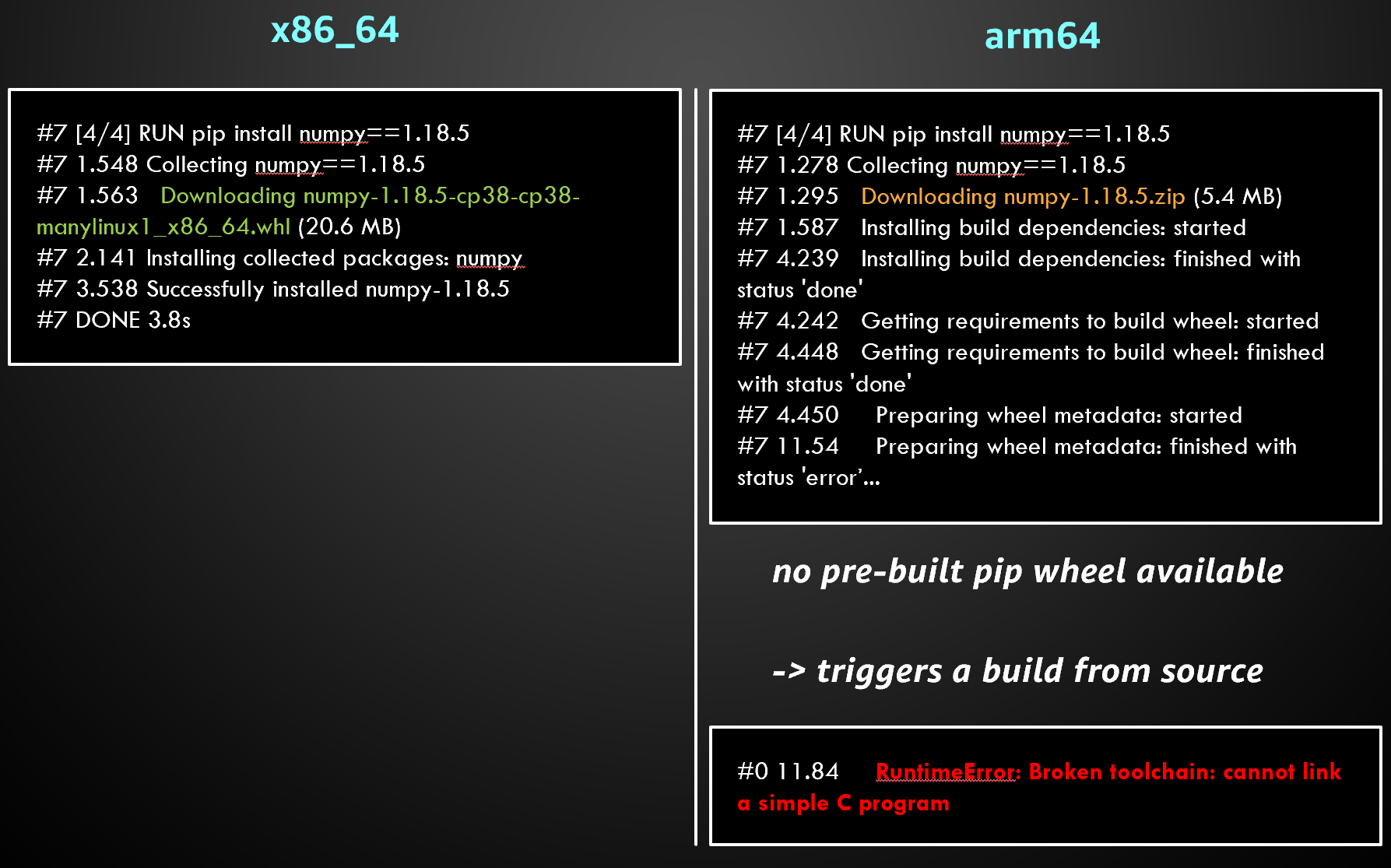
An option is to install in the Dockerfile all the dependencies required to build the source code. A better option is to upgrade numpy to 1.19.0 which is the first version to add arm64 pip wheels. This would make the Dockerfile consistent between x86_64 and arm64.
Latest software version, but no binaries
Case 1 - Package
node-canvas v2.11.2 is a Node.JS package containing C++ code (it requires a binary compatible with the CPU architecture).
In the x86_64 build, the following will suffice:
FROM public.ecr.aws/amazonlinux/amazonlinux:2023
# RUN install prerequisites like nodejs
RUN npm install canvas
However, in the arm64 build, as there is no binary published, npm will attempt to build from source (it requires build dependencies).
FROM public.ecr.aws/amazonlinux/amazonlinux:2023
# RUN install prerequisites like nodejs
# In prod, consider multi-stage builds
RUN yum install -y gcc-c++ cairo-devel libjpeg-turbo-devel pango-devel giflib-devel
RUN npm install canvas
Case 2 - Library for a package
The Python module confluent-kafka v2.0.2 needs to be built from source on arm64 like in the first case.
But also, one of its dependencies, librdkafka, written in C, doesn’t provide an arm64 binary either.

So the x86_64 build that would only contain pip install confluent_kafka becomes on arm64 (an example):
FROM public.ecr.aws/lts/ubuntu:20.04_stable
ARG CKAFKA_VERSION="2.0.2"
ARG LIBRDKAFKA_VERSION="2.0.2"
# In prod, consider multi-stage builds
RUN apt update && \
apt install -y --no-install-recommends git build-essential python3-pip python3-dev && \
git clone -b v${LIBRDKAFKA_VERSION} https://github.com/confluentinc/librdkafka && \
cd librdkafka && ./configure --install-deps && \
make && \
make install && \
ldconfig && \
pip install confluent-kafka==${CKAFKA_VERSION} --no-binary :all:
Application code uses low-level constructs
Compiled languages offer ways to implement performance optimizations that are specific to a CPU’s ISA. Typically, they’re done automatically using compilers (by changing versions and flags), but they can be implemented manually too.
A simple example would be the runtime test suite for a Go package. The following is the x86_64 build:
FROM public.ecr.aws/lts/ubuntu:20.04_stable
# RUN install prerequisites and download https://github.com/segmentio/parquet-go.git
RUN go test -tags amd64 -v ./
The tag will enable code paths that use x86_64 specific constructs (example: https://github.com/segmentio/parquet-go/blob/main/page_max_amd64.s). This will fail on arm64.

The developers added another tag that will not use the x86_64 code which will work on arm64:
FROM public.ecr.aws/lts/ubuntu:20.04_stable
# RUN install prerequisites and download https://github.com/segmentio/parquet-go.git
RUN go test -tags purego -v ./
Performance
While having multi-arch container images is great, one will wonder when to choose x86_64 over arm64 for deployments.
Ideally, you’d want to use the right compute choice for your software workload, but this requires performance analysis.
The topic is complex and outside of the scope of just discussing multi-arch images, however knowing a few high-level tips can help:
- rely on performance monitoring tooling when you can, though not all of them are container level-aware (some will only report host stats which can be an issue in shared environments)
- to compare 2 different CPU architectures, you need to measure relevant metrics like requests/s or job time, not CPU utilization (which should be workload max-ed during testing)
- do performance testing under production-like conditions for input data, throughput, latency, etc.
Summary
Thanks to cloud compute options based on arm64 which tend to be more cost effective and energy efficient, more container images and other software packages get built and published for arm64.
Most popular container images available in public registries will already be multi-arch and they tend to support both x86_64 and arm64, as well as other popular CPU architectures as needed.
Container orchestration software like Kubernetes benefits from multi-arch images as it simplifies deployments and if you have K8s clusters on the cloud, you should consider this option.